Synthèse : ChatGPT s’est servi des sites web pour devenir performant et omniscient. Les sites web sont dépossédés de leurs créations et n’en reçoivent aucun trafic. OpenAI, société privée, exploite nos ressources pour son propre profit. Refuser ce modèle est possible en empêchant ChatGPT de s’améliorer – lui interdire d’explorer vos sites.
Sommaire
1 – Le web face à la nouveauté des assistants IA
Le web c’est vous. Votre site est votre propriété, vous pouvez en autoriser la lecture à qui vous le souhaitez – internautes ou logiciels, humains ou robots.
Distinguons trois profils :
- les internautes – votre public, votre audience, votre cible, vos clients finaux. C’est pour eux que le site existe : afin qu’ils achètent vos produits, souscrivent à vos services, gardent votre marque en tête. Ils explorent votre site par un navigateur.
- les moteurs de recherche – ils explorent votre site pour en inclure ses pages dans leur index, et les proposer à leurs utilisateurs dans leurs résultats de recherche. Ils apportent de la visibilité et du trafic à votre site, gratuits puisque les moteurs sont autonomes (pas besoin de partage actif ou de campagnes) et sont au final des répertoires de pages, des intermédiaires entre l’internaute et votre site.
- les assistants IA – ils agrègent le contenu des sites afin d’ « apprendre » un sujet pour pouvoir le restituer à leurs utilisateurs. Ce sont des moteurs de réponses directes : ils ne répertorient pas les pages web, ne sont pas des intermédiaires car toute l’expérience utilisateur se fait en interne. Google a progressé vers ce modèle sur certaines verticales, par exemple par la recherche vocale et les réponses directes sur des éléments factuels. Aujourd’hui ChatGPT en est l’exemple absolu et l’acteur principal.

1.1 – Faisons une analogie avec un livre
- un lecteur trouve, achète et lit votre livre
- un libraire guide le lecteur dans sa recherche de livre, que le lecteur achètera
- un intellectuel s’adresse à son audience à propos d’un sujet qu’il a appris grâce à votre livre, qu’il a consulté gratuitement, et n’y fais pas référence. Cette personne est désormais la référence.
Dans la vie réelle comme dans le monde digital, l’intellectuel / l’assistant est votre adversaire :
- Vous avez patiemment produit de l’information, de la connaissance, sur la base de votre compétence et de votre expérience.
- Vous avez choisi de la partager au monde, avec en tête votre public.
- Vous concédez le droit à des intermédiaires de la référencer pour la rendre plus visible à votre public cible, en échange d’une mise en avant de votre site.
- Dans le cas d’un assistant IA, vous concédez votre connaissance en échange de rien.
C’est le sens du procès intenté par plusieurs auteurs aux USA à ChatGPT (lire plus bas)
1.2 – Dans le web moderne
- Vous êtes un média en ligne : journalistes, reporters, experts et invités travaillent à temps plein pour publier de l’information et diffuser des connaissances, parfois exclusives.
- Vous êtes un blogueur indépendant écrivant sur sa passion : vous êtes un média en ligne
- Vous êtes un site de marque : vous cherchez à être reconnu dans votre secteur grâce à votre section éditoriale, informative, qui a mobilisé des ressources et du temps.
- Vous êtes un site e-commerce : votre site est un intermédiaire entre l’internaute et votre catalogue de produits physiques, ils ne sont pas menacés
Cas concret en août 2023 : le New York Times (média en ligne) songe à poursuivre OpenAI en justice face à l’utilisation de ses reportages par ChatGPT. Comme le résume NPR : « ChatGPT devient un concurrent direct du journal en créant un texte qui répond aux questions sur la base du reportage original et de la rédaction du personnel du journal. »

2 – Le web a nourri ChatGPT qui menace de le remplacer
Bref: votre site et votre contenu ont été prévus pour être mis à disposition de votre public, soit directement, soit par des intermédiaires contrôlés. ChatGPT l’exploite pour le mettre à disposition de son propre public. Il est encore possible de refuser le déséquilibre pour rester propriétaire de votre travail.
2.1 – Note technique : votre site est majoritairement exploré par des robots
Consulter les visites réelles sur le serveur de son site est toujours une surprise les premières fois : les internautes sont minoritaires face à des robots d’exploration divers, rarement identifiables, souvent parasitaires. On a notamment :
- des moteurs de recherche mettant à jour leur index (base de données) – les existants (Google, Bing) ou des entrants minoritaires (Neeva)
- des services parasites copiant nos images et contenus pour créer des sites poubelles
- des outils créant leur propre index pour en faire un service commercial : SEMrush, Ahrefs, Majestic, Babbar…
- des robots d’archivage, comme Internet Archive et Common Crawl
Si on en revient à la finalité de notre site, donc de notre contenu mis à disposition sur internet, on doit se poser la question de l’utilité pour nous de tout ce passage. De quel droit des services commerciaux tiers se construisent-ils à l’aide de notre contenu ?
Dans le cas des moteurs de recherche, ce sont des intermédiaires entre les internautes et notre site. Dans le cas d’outils et d’archives, ils ne nous apportent rien. Pire dans le cas d’assistants comme ChatGPT : ils gardent leurs utilisateurs captifs en leur apportant la réponse directement.
2.2 – ChatGPT nous a mis devant le fait accompli
Bien que les solutions d’OpenAI soient connues et exploitées des professionnels depuis plusieurs années, la mise à disposition au grand public de ChatGPT en novembre 2022 a été une bombe médiatique – aussi bien pour les particuliers (un gadget amusant qui peut servir au quotidien ?) que pour les professionnels (ce chatbot peut-il accélérer mon travail ?). Un des défauts de l’outil est que ses connaissances s’arrêtent en 2021.
Ce qui veut dire deux choses :
- tout ce qu’il connait, il l’a appris de contenus existants, dont potentiellement les vôtres
- tout ce qu’il apprend en ce moment, il le prend potentiellement chez vous
ChatGPT a été un passager clandestin pendant plusieurs années, et il continue.
A-t-on autorisé une société privée à exploiter nos ressources pour son propre profit? Non.
Peut-on lui faire rendre ce qu’elle nous a pris ? Non plus.
En août 2023, ce passager clandestin nous révèle comment l’empêcher de rentrer chez nous.
2.3 – Deux sources à tarir pour ChatGPT : GPTBot et CCBot
2.3.1 – Le robot d’exploration de ChatGPT
Tout logiciel / navigateur / robot / crawler est identifié par un identifiant appelé l’User-Agent.
Cette information permet d’empêcher certains logiciels / robots d’explorer tout ou partie d’un site web. La pratique est courante en SEO, où l’on ne présente qu’une partie utile de notre site à un moteur de recherche. C’est le protocole robots.txt : des directives dans un fichier à la racine du site. Si un User-Agent non autorisé interroge une URL, elle lui sera refusée et il n’accèdera pas à son contenu.
GPTBot a été révélé par OpenAI en août 2023, annonçant qu’un robot d’exploration existait et que « Les pages web explorées avec l’User-Agent GPTBot peuvent potentiellement être utilisées pour améliorer de futurs modèles. »
Web pages crawled with the GPTBot user agent may potentially be used to improve future models
GPTBot – OpenAI API
Il est ici question notamment de la technologie qui rend ChatGPT performant, dans sa compréhension et son utilisation du langage. GPT veut dire ‘Generative Pre-trained Transformer » – l’IA a été entraînée pour comprendre le langage naturel et répondre aux questions qui lui sont posées. Les modèles GPT d’OpenAI existent depuis 2018, et sortent à intervalles constants :
- GPT (2018)
- GPT-2 (2019)
- GPT-3 (2020)
- GPT-3.5 (2022)
- GPT-4 (2023)
Cette technologie s’entraîne donc notamment sur nos sites web en ce moment-même.
2.3.2 – Common Crawl et sa copie conforme du web
On a appris plus tôt que ChatGPT a affiné sa technologie et a construit sa base de connaissances par le service Common Crawl – une copie de l’internet, mise à disposition gracieusement, à des fins de recherche et d’analyse. ChatGPT avait initialement annoncé que sa source étaient 570Gb de données, composées de livres, Wikipédia, articles de recherche, sites web…
Se basant sur des principes directeurs de transparence et d’égalité, Common Crawl annonce que
Chacun devrait avoir la possibilité de se livrer à ses curiosités, d’analyser le monde et de poursuivre des idées brillantes. Les petites startups ou même les particuliers peuvent désormais accéder à des données d’exploration de haute qualité qui n’étaient auparavant disponibles que pour les grandes sociétés de moteurs de recherche.
Curious about what we do? – Common Crawl
Everyone should have the opportunity to indulge their curiosities, analyze the world and pursue brilliant ideas. Small startups or even individuals can now access high quality crawl data that was previously only available to large search engine corporations. YOU need years of free web page data to help change the world.

Le remède s’annonce pire que le mal : la « petite startup » qu’est OpenAI a eu l’ « idée brillante » de mettre à disposition du public un chatbot surpuissant, un aggrégateur de toutes les informations du web dans un espace hermétique. OpenAI est de plus largement financée par Microsoft, une des deux fameuses « large search engine corporations ».
Supposons que ChatGPT s’appuie toujours sur cette source pour mettre à jour sa base, complété par son robot GPTBot, et bloquons les deux.
2.3.3 – Comment bloquer ChatGPT de son site web ?
L’action consiste à interdire l’exploration de votre site web à GPTBot et CCBot via le robots.txt
User-agent: CCBot
Disallow: /
User-agent: GPTBot
Disallow: /2.3.4 – Comment bloquer Google Extended de son site web ?
L’application Gemini (ex-Bard) de Google se développe sur le même modèle que ChatGPT, mais à l’amabilité de prévenir. Si l’on souhaite que nos sites contribuent à améliorer les API génératives des applications Gemini et Vertex AI, « y compris les futures générations de modèles qui alimentent ces produits », on veillera à laisser le libre accès à l’User-agent Google-Extended. Dans le cas contraire :
User-agent: Google-Extended
Disallow: /3 – ChatGPT contre le web, OpenAI contre le Droit
Le sujet n’est pas de s’enfermer dans un cocon pour se protéger de l’IA. Les solutions d’IA générative se développent depuis le début de l’année 2023 et sont parties pour être intégrées à nos usages quotidiens, en tant qu’outils indépendants ou intégrées à des usages existants.
3.1 – L’IA générative n’est pas une menace tant qu’elle ne vous efface pas
Chez les moteurs de recherche, Bing a intégré ChatGPT lui-même pour le faire bénéficier de son index à jour et améliorer l’expérience du moteur de recherche. Google travaille sur sa Search Generative Experience (SGE) avec sa technologie Bard. Ces ajouts sont des extensions de leur fonction de moteur de recherche : basées sur leurs indexes existants respectifs et citant leurs sources.
Comme vu plus haut, un moteur de recherche est un intermédiaire entre l’internaute et le site web, il n’a pas pour finalité de garder l’internaute dans son écosystème. Nous avons tous fait le choix volontaire de les laisser explorer et indexer nos sites web afin qu’ils les « réferencent » et les mettent en avant pour faciliter leur découverte.
ChatGPT en revanche a exploité nos sites web pour se nourrir lui-même et conserver l’internaute. Il ne citera jamais ses sources puisqu’il ne sait pas d’où proviennent ses connaissances. Si on pousse le raisonnement à l’absurde : plus il y a d’utilisateurs de ChatGPT, moins il y a de visiteurs de sites web.
3.2 – Réagir en attendant les actions en justice et la réglementation
Internet a le défaut d’être sans frontières, donc difficilement régulable par des législations par définition limitées à des pays et continents. Si une société crée une copie de Wikipédia à l’identique et y diffuse de la publicité, difficile d’agir contre si elle n’est pas établie dans un pays soumis à un droit du numérique.
3.2.1 – La presse, première concernée et première résistante à ChatGPT
4e site le plus présent dans la base de donnée utilisée par ChatGPT, le New York Times interdit l’exploration de son site à GPTBot et CCBot via son fichier robots.txt. Au 22 août, le NYT et OpenAI sont en discussion depuis plusieurs semaines à propos d’une compensation. La tendance est à un procès à venir. Comme le résume NPR :
ChatGPT devient, en un sens, un concurrent direct du journal en créant un texte qui répond aux questions sur la base du reportage original et de la rédaction du personnel du journal.
‘New York Times’ considers legal action against OpenAI as copyright tensions swirl
Les conséquences peuvent être radicales pour ChatGPT :
« si un juge fédéral constate qu’OpenAI a copié illégalement les articles du Times pour entraîner son modèle d’IA, le tribunal pourrait ordonner à l’entreprise de détruire l’ensemble de données de ChatGPT, obligeant l’entreprise à le recréer en utilisant uniquement le travail qu’elle est autorisée à utiliser. »
Moins offensifs, sans doute du fait de la nouveauté du sujet, certains médias se contentent de renvoyer à des conditions d’utilisation et d’exploration du site, au sein de ce même fichier robots.txt.
Le Monde :
Il est interdit d’utiliser des robots d’indexation Web ou d’autres méthodes automatiques de feuilletage ou de navigation sur ce site Web.
« Violation du droit du producteur de base de données – article L 342-1 et suivant le Code de la propriété intellectuelle ».
Le Financial Times
all use of FT content is subject to the Terms & Conditions and Copyright Policy set out on FT.com
Reporters Sans Frontières, déjà préoccupé par la qualité de l’information face aux transformations du journalisme à venir, invite tous les médias à se protéger en attendant un cadre réglementaire.
« RSF Invite les médias à configurer leurs sites d’information pour empêcher OpenAI de récolter leurs contenus gratuitement. »
📣RSF invite les médias à configurer leurs sites d'information pour empêcher #OpenAI de récolter leurs contenus gratuitement. Les médias doivent être rétribués pour leur travail d'intérêt général dont les mastodontes de la #tech voudraient tirer profits à bons comptes. https://t.co/YclmgpSCoP
— RSF_Tech (@RSF_Tech) August 8, 2023
En France, certains groupes de médias ont agi au coeur de l’été : les sites de France Médias Monde (RFI, Radio France…) et de TF1 bloquent ChatGPT. Le site actu.fr également, visant également les plugins utilisateur.
Plus inattendu, le géant de l’e-commerce mondial Amazon a bloqué GPTBot de tous ses différents sites.
Amazon just blocked the ChatGPT crawler on all their sites 👀
— Jan Caerels (@CaerelsJan) August 17, 2023
.com, .com.be, .nl, .fr, etc.#SEO #ChatGPT pic.twitter.com/kNkUp2EiLT
Et au 22 août 2023, 9% des sites du Top 1000 mondial l’ont bloqué, dont plusieurs sites majeurs :
Amazon, Quora, le NYTimes, Shutterstock, Wikihow & CNN
Selon une étude de la société Originality.ai la part de sites bloquant l’accès à ChatGPT est de 32% au 16 février 2024, sur un échantillon des top 1000 plus gros sites.

Les autres bots bloqués sont CCBot, évoqué plus haut, Google-Extended qui entraine les modèles pour Gemini et Anthropic-AI, le bot de la solution Claude AI.
3.2.2 – Les individus aussi nourrissent ChatGPT
When you use our non-API consumer services ChatGPT or DALL-E, we may use the data you provide us to improve our models.
We retain certain data from your interactions with us, but we take steps to reduce the amount of personal information in our training datasets before they are used to improve our models.
How your data is used to improve model performance | OpenAI Help Center
Utiliser ChatGPT, c’est le nourrir volontairement. Il est même précisé que les informations personnelles sont « réduites » mais clairement pas supprimées, comme le sont pour des outils de web analyse par exemple (soumis à la loi et la respectant). Or, en Europe et en France il existe un cadre réglementaire concernant les données personnelles, et les conditions d’utilisation de ChatGPT ne s’y conforment pas.
Dès le mois de mars, un pays entier a bloqué l’usage de ChatGPT. Les reproches de l’Italie à l’outil :
- Les craintes sur la sécurité des données personnelles,
- L’absence d’une note d’information aux utilisateurs,
- L’absence de filtre pour vérifier l’âge des utilisateurs.
Le pays remarque « qu’il n’y a pas de base juridique justifiant le recueil et la conservation en masse des données personnelles, dans le but d’entraîner’ les algorithmes faisant fonctionner la plateforme ».
3.2.3 – Deux actions en justice en France
L’association Janus International demande à la CNIL de l’aider à exercer son droit d’accès à ses informations personnelles collectées par OpenAI. Sa tentative auprès de la société n’ayant pas donné de suite.
Le développeur David Libeau a déposé une plainte à la CNIL, soulignant que ChatGPT invente des faits concernant les individus, ce qui contrevient à l’article 5 du Règlement européen sur les données personnelles (RGPD), selon lequel les informations sur des personnes doivent être exactes.
3.2.4 – Aux USA, plusieurs actions en justice d’écrivains
Sarah Silverman, Christopher Golden et Richard Kadrey attaquent en justice OpenAI et Meta, estimant que leurs modèles ont été entraînés sur des bases de connaissances comportant leurs ouvrages illégalement. ChatGPT est donc en mesure de résumer leurs livres, sans leur consentement.
Par souci de concision, on évoquera rapidement le pendant visuel de ChatGPT : les modèles de génération d’images, visés par des plaintes d’artistes dont les œuvres ont servi à entraîner ces modèles.
3.2.5 – Mais en fait, c’est toute la connaissance écrite de l’humanité qui est privatisée ?
Si on élargit le raisonnement comme l’activiste altermondialiste Naomi Klein, “les IA organisent le plus grand pillage de l’histoire de l’humanité”.
Ce à quoi nous assistons est :
- l’accaparement de la somme des connaissances de l’humanité existantes sous forme digitale
- par les entreprises les plus riches de l’histoire
- pour les intégrer à leurs produits propriétaires
What we are witnessing is the wealthiest companies in history (Microsoft, Apple, Google, Meta, Amazon …) unilaterally seizing the sum total of human knowledge that exists in digital, scrapable form and walling it off inside proprietary products.
AI machines aren’t ‘hallucinating’. But their makers are | Naomi Klein | The Guardian
3.3 – Le lobbying d’OpenAI, Microsoft et Google pour atténuer la réglementation européenne à venir
La Commission européenne n’a pas attendu l’apparition de l’IA grand public pour travailler sur le sujet. Depuis 2018, se sont succédé un groupe d’experts et plusieurs Assemblées européennes pour aboutir à la création d’une Alliance européenne de l’IA et une « Législation sur l’intelligence artificielle » (Artificial Intelligence Act).
Le magazine Time a pu obtenir des documents internes à la Commission européenne et a constaté que plusieurs amendements proposés par OpenAI ont été repris par le texte final, base de négociation sur la législation à venir. Ce n’est ni une surprise, ni une nouveauté, Microsoft et Google étant présents sur le sujet depuis au moins 2022.
Le fond du débat porte sur la responsabilité de l’usage des IA – une IA à portée générale est-elle dangereuse par sa conception ou par son utilisation ?
Savoir que les créateurs des IA sont à la fois juge et partie doit nous conforter dans une position de précaution.
4 – Brider ChatGPT pour préserver notre travail
L’effervescence autour de l’IA grand public est compréhensible. Chaque secteur estime pouvoir intégrer une partie d’IA dans ses processus de travail et son offre commerciale ; les particuliers sont grisés par la facilité d’accès à l’information et à la génération d’images.
Il est souhaitable de prendre du recul sur le sujet, comme nous savons le faire avec nos objets du quotidien. Nos vêtements et nos outils numériques ont en général un bilan humain et écologique majeur, et nous cherchons à limiter les dégâts voire à inverser la tendance (relocalisation, réparations…). Une prise de conscience sur ces solutions d’intelligence artificielle générative nous amènerait à se poser les bonnes questions :
- qui a contribué à rendre ces outils aussi performants ?
- ont-ils contribué volontairement ?
- ont-ils été rétribués pour leur contribution ?
- souhaite-t-on laisser ce modèle se développer ?
ChatGPT devient un concurrent direct des sites, médias, journalistes et créateurs qu’il a lésé. Il conserve le fruit de leur travail (de votre travail) pour le proposer à ses propres utilisateurs, parfois abonnés payants, sans compensation pour la source.
Internet est la somme de toutes nos contributions : contenus personnels, articles de presse, sites marchands, blogs, réseaux sociaux… Nous avons fait le choix d’y contribuer, de l’animer, de faire ce qu’il est, en échange d’une audience et de clients. Ce que ChatGPT propose comme modèle est :
- d’exploiter nos contributions
- pour son propre intérêt
- en échange de rien
CNN, Amazon et le NYT l’on fait, à vous de décider de rejoindre le mouvement et de bloquer ChatGPT.
5 – 2026 : les médias face à trois types de bots IA : entrainement, recherche, indexation
Quasiment trois ans plus tard, l’apport potentiel des moteurs de recherche IA est le sujet majeur du digital. La visibilité dans les moteurs est une angoisse et/ou une priorité pour les marques, malgré l’apport minime en terme de trafic réel. Les sites médias restent néanmoins menacés par les IA : une synthèse d’une actualité dans ChatGPT / Gemini / Perplexity implique une visite en moins pour l’article source, et donc une vue en moins pour la publicité (revenu principal des médias), et les bots IA arrivent parfois à contourner les paywalls.
I y a néanmoins des partenariats signés entre certains médias et des IA, en France notamment : Le Monde avec OpenAI et Perplexity, l’AFP avec Mistral. Mais sans contrepartie, aucun intérêt pour un média de se faire siphonner son travail.
Trois types de bots sont des menaces :
- Bots d’entrainement – exploitent les contenus pour entrainer leurs modèles, méthode de construction des bases de connaissances des IA à leur lancement : CCBot, ClaudeBot, GPTBot
- Bots de recherche – explorent les pages web lors d’une recherche utilisateur : ChatGPT-User, Claude-Web, OAI-SearchBot
- Bots d’indexation – construisent un index autonome pour leurs IA respectives, pour l’instant uniquement Perplexity : PerplexityBot
Une étude de décembre 2025 de BuzzStream fait le point sur le blocage des bots IA par les grands médias anglophones.
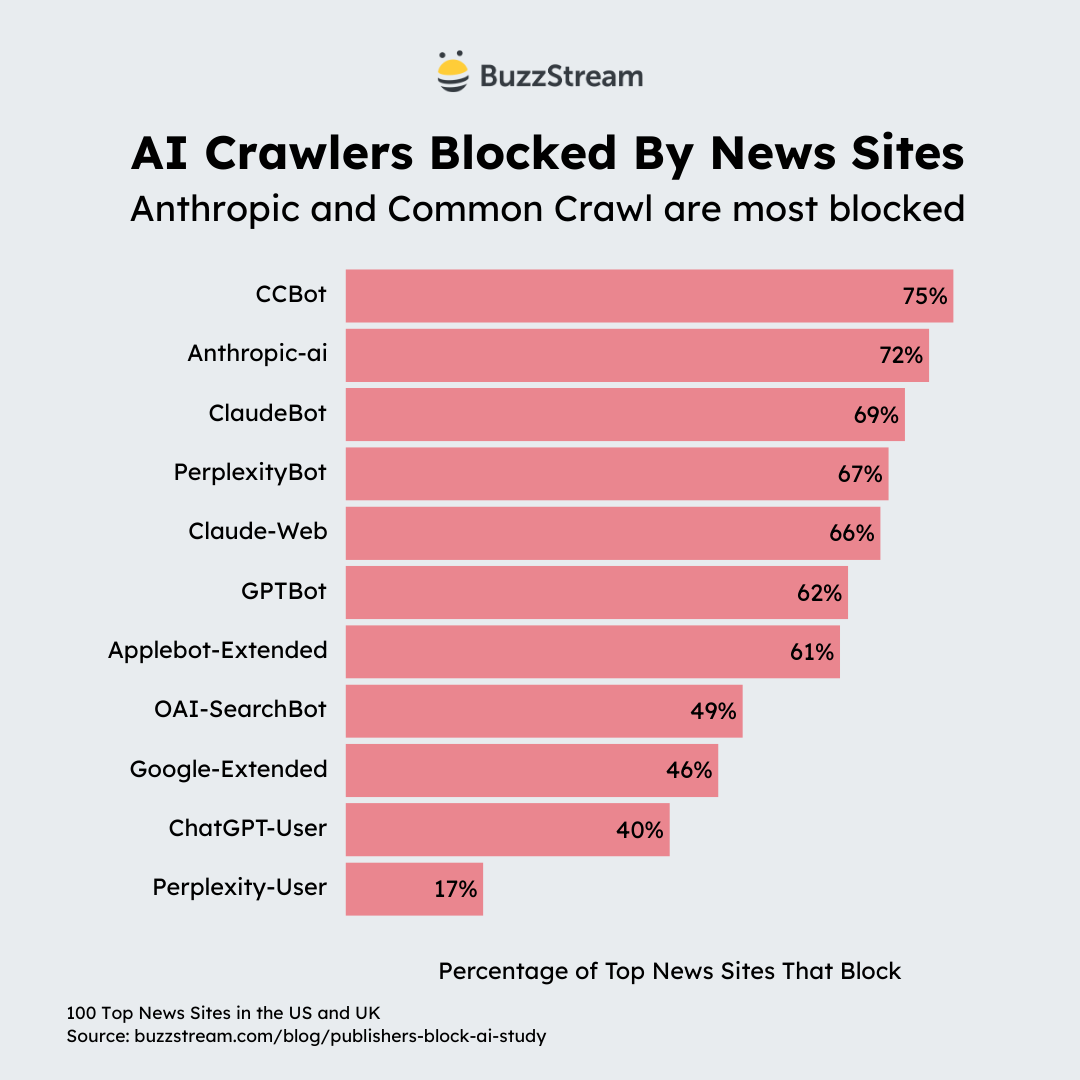
- CCBot, le bot de CommonCrawl (cf plus haut) est le plus bloqué.
- Anthropic / Claude et ses 3 bots (deux d’entrainement, un de recherche) est bloqué à ~70%.
- Les sites empêchent Perplexity de créer son index à leur dépens (67%), mais laissent ses utilisateurs bénéficier de leur contenu (Perplexity-User bloqué à 17%)
Le détail de l’étude est complet, présente des statistique sur les 3 types de bots, et souligne la limite de la méthode du robots.txt. Les IA conservant leurs pratiques déloyales d’origine ne respectent pas toujours les consignes du robots.txt, d’où des méthodes plus avancées de blocage, par exemple par Cloudflare.
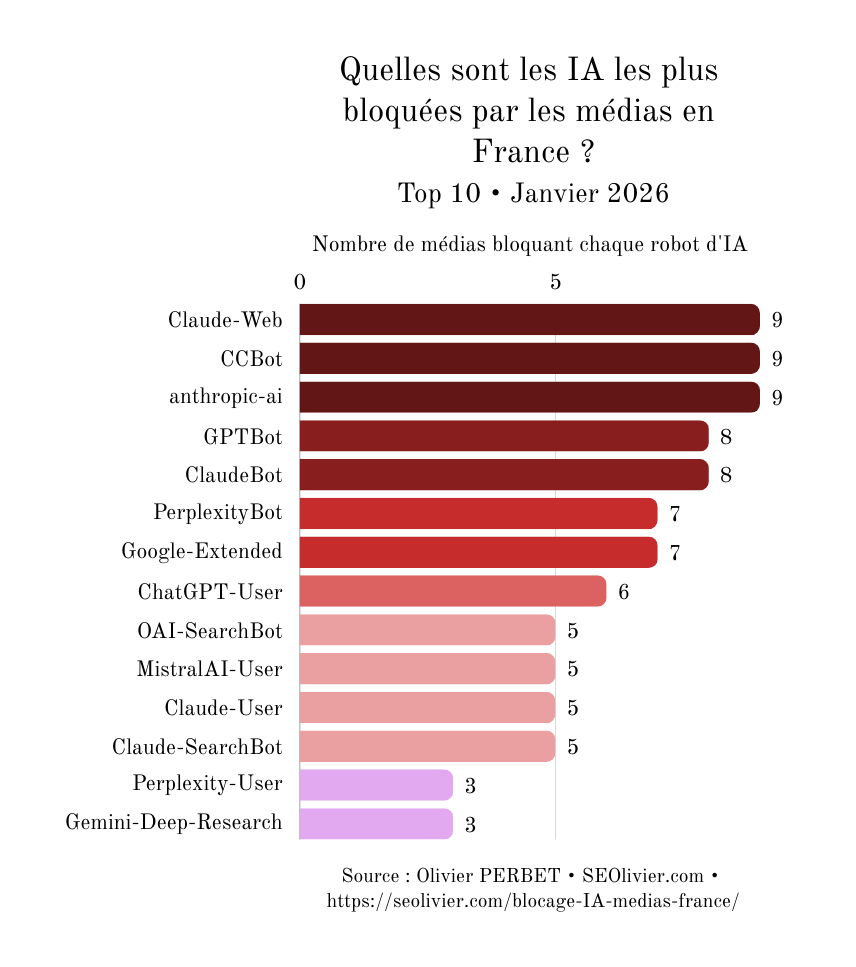
Et en France ? Une étude personnelle a fait le travail sur le blocage des bots IA par le Top 10 des médias en France.