Dans les facteurs de compréhension d’une page web par les LLM selon les sources académiques : les données structurées JSON-LD ne sont pas présentes.
Sommaire
1 – Le problème des SEO face aux données structurées
Les données structurées sont un sujet qui fait consensus en SEO.
Malheureusement.
C’est à dire qu’on admet sans y réfléchir que « les données structurées facilitent la compréhension d’une page web pour les moteurs de recherche ». On les intègre à nos sites au maximum, ou pire, on recommande à nos clients de les intégrer au maximum.
Il y a bien des formats de données structurées nécessaires (Produit, avis établissement local, organization, voire cas particuliers) qui sont recommandés par Google qui en échange nous donne accès à des affichages enrichis (Rich Snippets) dans ses résultats de recherche ou à Google Shopping. Utiles également pour renforcer l’existence d’une marque ou d’un établissement physique. La relation de cause à effet est démontrée.
Aparté : si on prend du recul et qu’on raisonne sur le temps long et l’évolution de Google, on se rend compte que d’avoir fourni le contenu de nos sites web sous forme de métadonnées a permis à Google de développer sa compréhension des choses (le KG, tout ça) et de créer ses services concurrents à nos sites.
Mais trop couramment, le SEO (white hat) va chercher à aller plus loin, et à baliser le maximum d’informations de sa page en allant chercher les formats les plus ésotériques dans la base schema.org. Qui n’existe que pour elle-même : elle ne promet pas un quelconque avantage à intégrer ces formats.
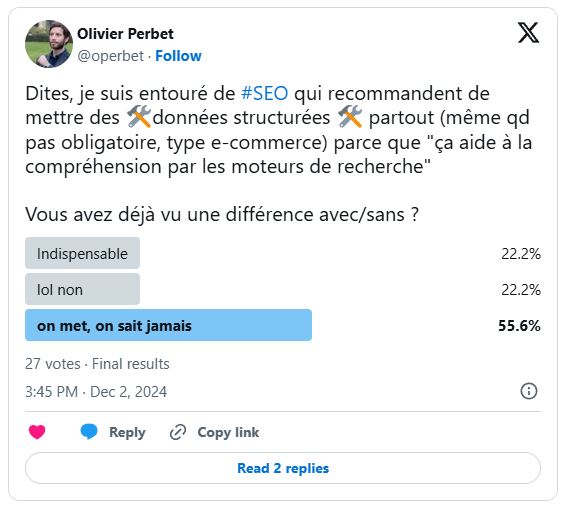
Alors pourquoi se force-t-on à en intégrer le maximum ? A conserver des formats obsolètes (Breadcrumb, FAQ), à se faire dicter la loi par des plugins et outils SEO alarmistes ? Intégrer une roadmap SEO dans le temps annoncé initialement est déjà un exploit, faire perdre du temps et des ressources à son équipe technique ou à celle de son client pour des résultats non mesurables est une aberration du métier qui dure depuis bien 15 ans.
Soyons mieux que des perroquets et des commerciaux
Il y a beaucoup de problèmes de fond dans la compréhension des moteurs de recherche dans la communauté SEO :
- la confiance aveugle dans les solutions techniques (plus il y a de code ou de technique, mieux la page est « comprise »
- la reprise telle quelle d’affirmations d’autres personnes / agences / outils à qui on attribue une autorité
- le parasitage alarmiste et maximaliste des outils SEO et plugins des CMS
- la surinterprétation de propos de gens internes au système (chez Google ou Bing)
- la répétition de lieux communs, de choses admises par la majorité en SEO, par facilité / confort
- la malhonnêteté – on sait que ce qu’on recommande ne fait rien, mais… (cf infra)
- la fuite en avant commerciale : davantage de recos à faire intégrer = davantage d’heures à vendre au client
On a la chance d’être dans un métier où faire ses propres tests ne coûte quasiment rien – montez votre site web dans une niche, regardez comment il se comporte, intégrez des JSON-LD partout, faites un PBN autour… Il y a en plus une richesse incroyable de méthodes possibles, autant d’approches qu’il y a de professionnels du SEO. Pourquoi ne pas construire ses propres raisonnements sur la base de sa propre expérience professionnelle ?
Un lourd passif quant aux idées reçues en SEO
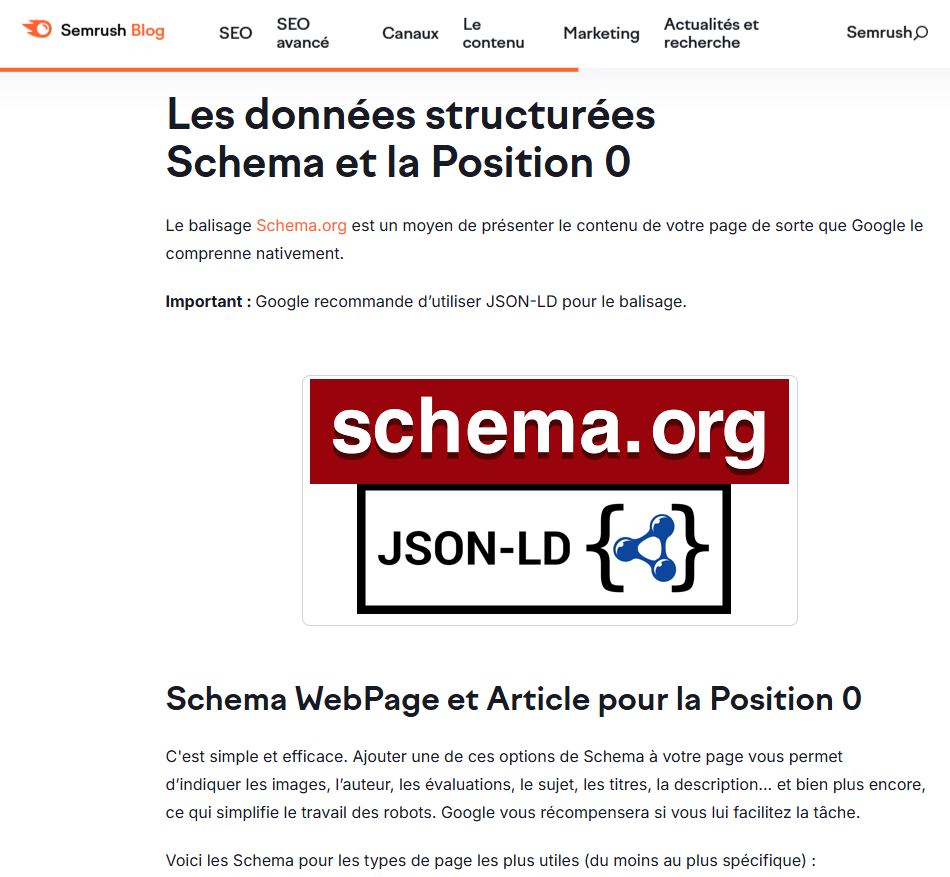
Rien que sur les données structurées, on leur attribue un rôle magique pour toutes les nouveautés que Google crée dans les SERP. En 2018 par exemple sur le Blog de SEMRush, dans un article Techniques avancées pour gagner la Position 0 (Featured Snippet) : un article extrêmement flou, qui sous-entend plus qu’il n’affirme, mais le mal est fait.
Amplification de l’imposture : les SEO sont devenus des experts en IA du jour au lendemain
(Le « jour » en question était très souvent en novembre – décembre 2022, suivez mon regard).
On avait donc des affirmations fausses en SEO depuis 20 ans, les voici dans le domaine des LLM. Il y a bien des dizaines de sujets différents à travailler et comprendre dans ces boites noires qui évoluent en permanence, mais tant qu’on ne sait pas, on peut avoir la politesse de ne pas nuire.

- « JSON-LD » […] helps LLMs understand content context
- Preuves :
- Une citation de Fabrice Canel de Bing, cité par le post LinkedIn de quelqu’un dans le public au SMX. Détail ? Aucun. Démonstration ? Aucune.
- Une supposition basée sur le comportement des AIO chez Google
- Une autre supposition sur le fonctionnement des bots d’OpenAI
Et un autre, d’une société dont le métier est l’intégration de données structurées, estime que le fonctionnement de base des LLM (la tokenisation) est obsolète grâce aux « progrès de l’IA en 2025 » qui seraient de plus en plus capable d’exploiter les données structurées. Qui sont donc le futur de la visibilité dans les IA, CQFD. Des preuves de ces affirmations ? Aucune.

Google et Bing en faveur de Schema.org pour leurs propres IA – une confusion qui n’aide pas
Google, habitué des grands principes flous
Google a eu l’occasion récemment d’aborder le sujet, mais de la manière la plus vague et la moins engageante possible. Ca peut tout vouloir dire comme son contraire, et une bonne partie des articles récents sur le sujet (Données structurées et IA) prennent ce propos comme source.
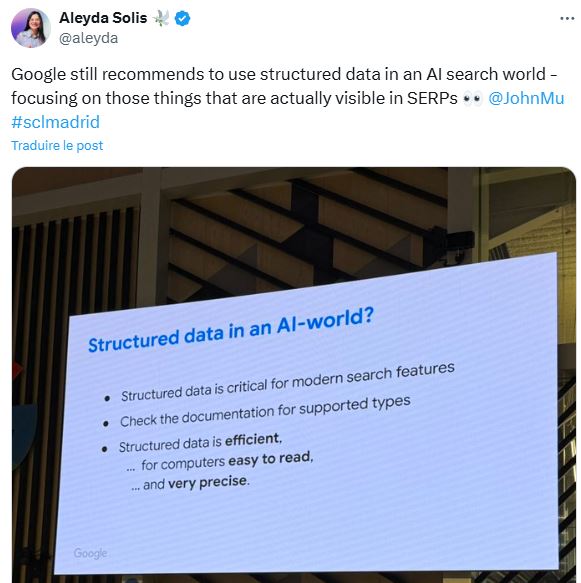
D’une manière générale, ne faites pas confiance aveuglément à Google. Les Google Leaks ont clairement montré l’existence de facteurs de positionnement que Google démentait depuis des années, par exemple. Et dans le cas précis des AIO, Google affirme qu’ils apportent davantage de trafic aux sites web qu’avant leur déploiement. En contradiction totale avec la réalité, chiffrée et démontrée.
Bing, des traces écrites mais pas plus précises
Bing dans un article de blog du 10 octobre 2025 « Optimizing Your Content for Inclusion in AI Search Answers » propose une section « How Does Schema Markup Help AI Understand Your Content? « . La réponse va vous étonner :
- « Schema is a type of code that helps search engines and AI systems understand your content » – le balisage Schema (.org) aide les moteurs et les IA à comprendre votre contenu.
- « …turning plain text into structured data that machines can interpret with confidence. » – le texte d’une page balisé en données structurées serait donc plus fiable.
Un contenu mal compris par les moteurs serait logiquement mal positionné, Schema serait nécessaire pour garantir une compréhension totale. SAUF qu’il n’y a aucune corrélation entre présence de données structurées et positionnement d’une page. Pourquoi ce serait davantage vrai pour les IA ?
Il est probable que Google et Bing ne parlent que de leurs propres technologies d’IA :
- Gemini & la SGE pour Google
- Copilot pour Bing
Ces IA sont uniques puisqu’elles se servent des indexes des moteurs de recherche, en quelque sorte comme une surcouche conversationnelle des résultats de recherche traditionnels. Et les données structurées aident à comprendre les entités et à les distinguer entre elles. Donc ce qui est valable pour un index de pages web est valable pour une IA qui le consulte.
Mais quelle serait la logique pour ChatGPT qui n’a pas d’index ?
Le « GEO » est nouveau, mais mérite qu’on prenne le temps de réfléchir et de chercher
Faire ses propres recherches prend du temps, répéter ce qu’on a lu c’est plus rapide, mais ça a ses limites. Malgré toute l’attention que reçoit ChatGPT et les dizaines de solutions de mesure de la visibilité d’un site dessus, on dirait qu’une seule personne au monde s’est rendue compte que SearchGPT s’appuie sur les résultats de Google. C’est Alexis Rylko qui mérite une fois de plus des remerciements pour son apport à la science du SEO et au rayonnement de la France dans le métier.
Bon mais les données structurées en JSON-LD dans les IA, ça marche ou non ?
Les biais et défauts des professionnels du web sont ce qu’ils sont. Si on veut étudier le sujet avec un minimum de sérieux, il faut aller chercher des sources qui :
- connaissent le sujet
- n’ont rien à nous vendre
Donc si on élimine comme sources :
- les médias SEO (Search Engine Journal)
- les vendeurs de solutions de données structurées
- les blogs d’agences SEO
Et qu’on insiste sur des sources académiques (papiers de recherche), sachant que l’IA est une expertise réelle et avancée qui date d’avant 2022, on peut supposer qu’on aura une réponse objective et argumentée.
On va donc demander à une IA de traiter le sujet : Les IA ont-elles besoin de JSON-LD pour comprendre une page ?
Etrangement, les LLM sont incapables de répondre à des questions sur eux-mêmes sans avoir à demander à d’autres sources ce qu’elles en pensent. Et bien c’est ce qu’on va faire, par le mode Recherche de Perplexity Pro, avec la consigne suivante :
Peux-tu classer les facteurs de compréhension d’une page web par les LLM selon des sources académiques, qui ne sont pas des sites SEO, de marketing digital ou d’agences de visibilité ?
2 – Facteurs de compréhension d’une page web par les LLM selon les sources académiques
(Synthèses et légères simplifications personnelles pour aider à la lecture).
Les facteurs de structure et de sémantique
1 – La structure du discours et les relations rhétoriques
Les LLM interprètent une page web principalement à travers l’analyse de sa structure discursive, qui comprend :
- Relations de subordination : comment les blocs de contenu s’organisent hiérarchiquement (titre → sous-titre → paragraphe)
- Relations de coordination : comment les éléments de même niveau se rapportent entre eux (séquence, parallélisme, contraste, rupture thématique)
- Unités de discours élémentaires : des blocs physiques cohérents sémantiquement (paragraphes, listes, légendes)
2 – La cohérence sémantique des blocs de contenu
L’efficacité des LLM dépend fortement de la cohérence sémantique interne des blocs de contenu, qu’on peut détailler en trois points :
- Homogénéité de mise en forme : les blocs sont visuellement distincts avec des limites claires
- Cohérence sémantique : le contenu est cohérent au sein de chaque bloc
- Consistance thématique : le maintien d’un sujet cohérent, une transition claire entre les sujets
Les facteurs techniques de prétraitement
3 – L’extraction et la simplification du HTML d’une page
Les études soulignent l’importance des techniques suivantes :
- Extraction de sections : sélection de portions HTML pertinentes autour d’éléments saillants
- Nettoyage du HTML : suppression du bruit (JavaScript, CSS, publicités)
- Compression intelligente : réduction de la taille tout en préservant l’information structurelle
- Élagage par arbre de blocs : méthode en deux étapes pour conserver uniquement les parties pertinentes
4 – La surcouche des XPath et les métadonnées
Les encodeurs XPath enrichissent la représentation des nœuds au-delà du texte :
- Chemin hiérarchique dans le document HTML
- Position spatiale et métadonnées de rendu
- Informations de bounding box pour la localisation visuelle
5 – L’intégration multimodale pour compléter
L’ajout d’informations visuelles améliore les performances de compréhension des LLM :
- Captures d’écran pour la compréhension spatiale
- Correspondance entre les éléments HTML et leur rendu visuel
- Modèles de type Faster R-CNN pour la détection et l’encodage visuel des éléments
Des métadonnées supplémentaires sont-elles nécessaires ?
Les LLM sont par définition et par démonstration capables de déduire la structure sémantique d’un contenu riche (comme une page web) à partir du contenu textuel et de la hiérarchie HTML.
Ce qu’on trouve en cherchant précisément le sujet des données structurées JSON-LD :
- Aucune étude comparative entre des pages web avec et sans JSON-LD pour l’extraction d’informations par LLM
- Aucune recherche sur l’utilisation de JSON-LD comme signal d’aide pour les tâches de raisonnement des LLM (NB : information complémentaire)
Les sources sur lesquelles s’appuient Perplexity :
- Understanding HTML with Large Language Models
- T. A. Santoro et al., 2022, arXiv:2210.03945.
- Étude sur la compréhension du HTML par les LLM, soulignant les architectures efficaces et les techniques de prétraitement.
- WebDP: Understanding Discourse Structures in Web Documents
- G. A. Iglesias et al., 2023, ACL Anthology.
- Analyse de la structure discursive, des relations rhétoriques et unités discursives élémentaires dans l’interprétation des pages web.
- A Large Language Model-based Web Navigating Agent
- X. Li et al., 2023, arXiv:2404.03648.
- Techniques d’extraction et de nettoyage de contenu HTML pour optimiser la compréhension contextuelle des LLM.
- HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Documents
- P. Gupta et al., 2024, arXiv:2411.02959.
- Importance de la structure visuelle et du contexte multimodal pour la compréhension des pages web.
- Scaling Instruction-Tuned LLMs to Million-Token Contexts via Chunked Cross-Attention
- A. Smith et al., 2023, arXiv:2504.12637.
- Recherche sur l’amélioration du traitement des dépendances longues, avec une application aux documents web de grande taille.
Aparté : même les pauvres IA en mode super-intelligent inventent des choses et ont besoin d’être recadrées.
3 – Faute de preuves, les IA n’ont pas besoin de JSON-LD
Bref, tant que je ne vois pas d’étude de cas, de démonstration avant/après ceteris paribus ou de recherches croisées démontrant un lien entre présence de données structurées et visibilité dans les IA, je considèrerai ça comme un mensonge (hors hypothèses des IA dédiées de Google et Bing).
L’espoir existe, je l’ai rencontré
La référence qu’est Search Engine Journal a le défaut de proposer des articles contradictoires, laissant souvent le champ libre aux défauts de la communauté SEO vus plus haut. Dans un élan de lucidité néanmoins, on a eu le droit à une déconstruction du mythe :
The idea that it’s good to use Schema.org structured data to rank better in an AI search engine is not based on facts, it’s just fanciful speculation. Or it could be from a “game of telephone” effect where one person says something and then twenty people later it’s transformed into something completely different.
Search Engine Journal – SEOs Are Recommending Structured Data For AI Search… Why?
Une approche de l’exigence
Il y a en parallèle des tas de professionnels qui étudient ces sujets de visibilité dans les IA. Bien que ce soit une micro-fraction du marketing digital en terme de trafic, on en apprend tous les jours et c’est passionnant.
Le sujet des données structurées face à l’IA est en fait un faux débat : une société n’a qu’un seul site web, qui sera de toute manière conforme aux bonnes pratiques SEO et donc intègrera des données structurées. Le choix de les intégrer ou non ne se basera pas sur le gain théorique sur les IA.
Le sujet est plutôt la diffusion d’informations fausses. Ce n’est pas de l’agressivité envers ceux qui les propagent, c’est une approche de rigueur et de professionnalisme. Pourquoi ne pas demander des preuves face à des affirmations, ou à des idées reçues du métier ? On n’est pas là en tant que professionnels pour appliquer ce qu’ont pu faire d’autres avant nous, on est censés maitriser notre métier. Le SEO c’est très vaste, mais avec un minimum de connaissances maitrisées on peut proposer une stratégie de croissance cohérente. Pas besoin de regex dans le robots.txt.
En conclusion, en SEO général comme en SEO pour les IA, ce n’est pas parce que quelqu’un a écrit quelque chose qu’il faut le croire sans preuve ou le relayer sans réfléchir.